SQL 마지막 강의 주차 정리!
조회한 데이터에 아무 값이 없다면 어떤 식으로 대처해야할까?
테이블에 잘못된 데이터가 들어있을 수도 있고, JOIN을 했을 때 값이 없는 경우도 있다.
이런 상황일 때 데이터를 처리 할 수 있는 방법을 하나씩 알아보자.
없는 값을 제외해주기.
테이블을 조회하였을 때 없는 값이 포함되어 있으면 평균 연산을 하였을 때 제대로 된 값을 얻지못한다.
이론만으론 완벽히 이해하기 어렵기에 예시 Query문을 보며 이해해보자.
select restaurant_name,
avg(rating) average_of_rating
from food_orders
group by 1
예시 Query문은 food_orders 테이블에서 음식점별 평균 rating을 구하기 위해 작성 되었는데,

rating에 Not given 이라는 문자가 존재하며
Mysql에서는 사용할 수 없는 값을 때, 해당 값을 연산에서 제외시킵니다. >> 0으로 간주
이럴 때 Not given을 NULL로 바꾸어주자.
select restaurant_name,
avg(rating) average_of_rating,
avg(if(rating<>'Not given', rating, null)) average_of_rating2
from food_orders
group by 1
사용할 수 없는 값을 NULL로 바꾸면 연산에 사용되는 데이터에서 제외된다.
따라서 확실한 연산을 지정해주기 위해 NULL 문법을 이용하는 실습을 해보면,
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.customer_id is not null
left join을 사용하면 존재하지 않는 데이터는 NULL로 표시되고 where 절을 이용해 NULL값이 아닌 데이터만 불러오게 한다.
NULL을 제거 하지 않으면 데이터 결과값 아래로 내리면 위 사진과 같이 NULL이 존재하는 것을 확인할 수 있는데, NULL을 제거하면 데이터 결과창을 아래로 계속 내려도 NULL 값이 존재 하지 않는 것을 확인할 수 있다.
left join을 했지만 마치 inner join과 동일하게 결과가 나오는 것을 확인할 수 있다.
다른 값을 대신하여 사용할 수 있고 이때 사용하는 2가지 방법으로 나뉘는데,
- 다른 값이 있을 때 조건문 이용 : if(rating >= 1 rating, 대체값)
- null 값일 때 : coalesce(age, 대체값)
이해하기 쉽게 예시 Query문을 작성하면,
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
coalesce(b.age, 20) "null 제거",
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.age is null
위 Query문은 left join 했을 시 b.age에 NULL 값이 있을 경우 20살로 대체값을 넣는 것이고 대체값이 잘 들어갔는 지 확인하기 위해 where절을 이용하여 b.age가 null 값일 때만 결과를 나타내라고 작성하였고 그 컬럼명을 'null 제거' 로 설정하였다.
위 사진처럼 age가 null일 때 20으로 대처한 결과이다.
데이터가 비어있는 경우도 존재하지만 상식적이지 않는 데이터가 존재하는 경우도 있다.
예시로 우리 데이터 테이블을 확인해보면, 보통 음식 주문은 20세 이상인 성인이 경우가 많지만 데이터 테이블에는 2살과 같이 상식적이지 않은 데이터도 존재하고 결제 일자가 1970년대가 있기도 한다.
우리는 이러한 데이터를 구별해내기 위해 if문을 사용하여 값의 범위를 지정해줄 수 있다.
이 방법은 새로운 함수나 용어를 쓰는 것이 아니므로 예시 Query문 만으로 이해하고 넘어가자.
select customer_id, name, email, gendor, age,
case when age<15 then 15
when age>80 then 80
else age end "범위를 지정해준 age"
from customers
case when then 을 이용하여 age가 15살 아래면 모두 15살로 대체하고, 80세 위면 모두 80세로 대체한 걸 알 수 있다.
SQL로도 엑셀처럼 Pivot Table을 만들 수 있다!
Pivot Table은 우리가 데이터를 좀 더 알아보기 쉽게 배열하여 보여주는 것이다.
바로 실습 결과를 통해 어떤 형태를 가지고 있는 지, 어떻게 사용하는 지 알아보자.
1)음식점별 시간별 주문건수 Pivot Table 뷰 만들기(15~20시 사이, 20시 주문건수 기준 내림차순)
하나씩 차근차근 Query문을 작성해보자.
select fo.restaurant_name,
substr(p.time, 1, 2) hour,
count(1) cnt_order
from food_orders fo inner join payments p on fo.order_id = p.order_id
where substr(p.time, 1, 2) between 15 and 20
group by 1, 2
맨 처음 음식점별, 시간별, 주문건수를 작성해야하고 음식점과 시간을 알기 위해 join을 사용해야하고 각 음식점별, 시간별 이기 때문에 group by를 사용하여 결과를 나타내준다.
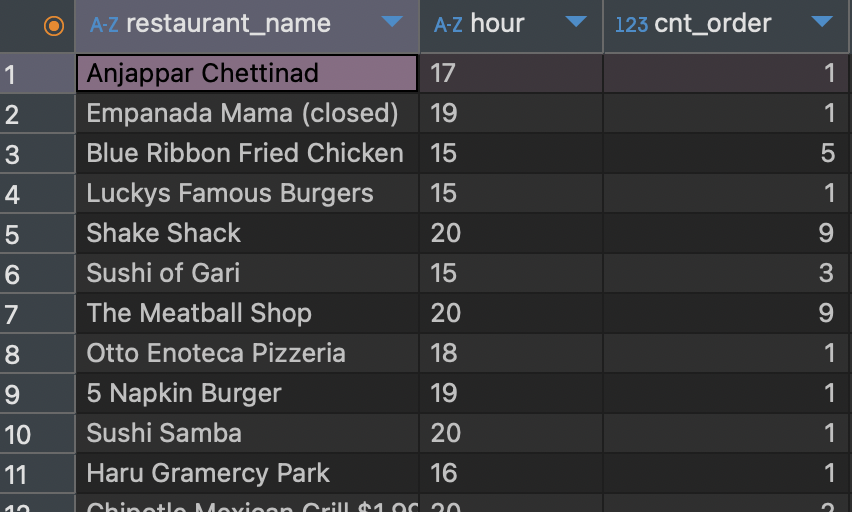
위 사진 처럼 우리는 앞에 시간대 별로만 필요하기 때문에 substr을 이용해서 time 컬럼의 첫번째 글자부터 2글자만 가져오게 한 다음 15시에서 20시 사이 주문건수만 필요하기에 where 절을 통해 조건을 만든다.
이렇게 원하는 결과를 만들었으니 다음으로 Pivot Table을 만들어보자.
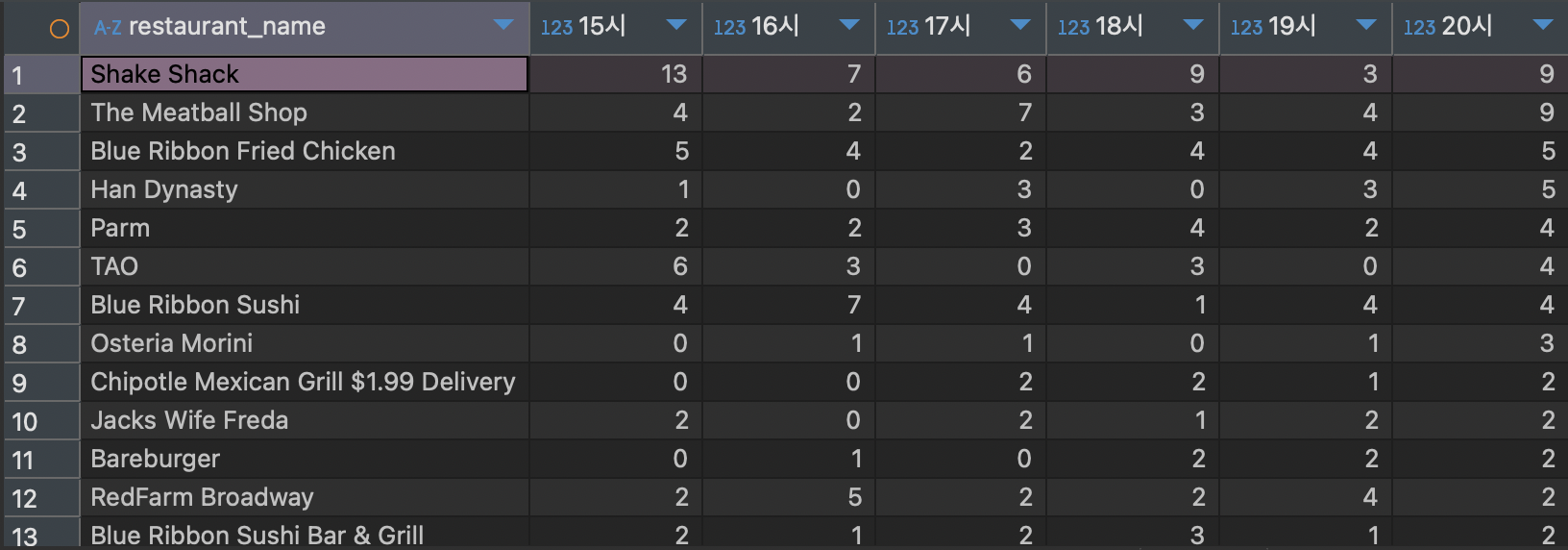
select restaurant_name,
max(if(hour = '15', cnt_order, 0)) "15시",
max(if(hour = '16', cnt_order, 0)) "16시",
max(if(hour = '17', cnt_order, 0)) "17시",
max(if(hour = '18', cnt_order, 0)) "18시",
max(if(hour = '19', cnt_order, 0)) "19시",
max(if(hour = '20', cnt_order, 0)) "20시"
from
(
select fo.restaurant_name,
substr(p.time, 1, 2) hour,
count(1) cnt_order
from food_orders fo inner join payments p on fo.order_id = p.order_id
where substr(p.time, 1, 2) between 15 and 20
group by 1, 2
) a
group by 1
order by 7 desc
Pivot Table을 만드는 방법은 max(if())을 이용하는 것인데, 나는 시간대 별로 주문 건수를 알고 싶기 때문에 if문 안에 시간대 조건을 만들어주고 그 조건이 맞다면 주문건수(cnt_order)를 나타내게 작성하고 그 컬럼명을 시간대로 작성해준다.
이러한 방식으로 20시까지 같은 문장을 만들어주면 결과는 아래 사진 처럼 나온다.
다음에는 Window Function -RANK, SUM의 기능에 대해 알아보자.
먼저 Rank 기능은 말 그대로 특정 기준으로 순위를 매겨주는 기능이다.
예시를 들면 주문이 가장 많은 순위 배달 시간이 빠른 순위 등등 이러한 순위를 정할 수 있다.
이 또한 실습을 통해 더욱 쉽게 이해해보자.
(실습을 진행할수록 Query문이 길어지지만 문제를 보며 문제가 요구하는 사항을 하나씩 해결해가면 어렵지 않게 할 수 있었다.)
1)음식 타입별로 주문 건수가 가장 많은 상점 3개씩 조회하기.
먼저 작성해야 하는 부분은 음식 타입별, 음식점별 주문 건수 데이터를 가져오자.
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
food_order 테이블에 모든 컬럼이 있으니 join을 사용하지 않아도 되고, 주문 건수이기 때문에 count(1)을 이용하여 주문 건수를 확인해주고 음식점별, 타입별이기 때문에 group by를 이용해준다.
이제 Rank 함수를 적용해줘야 하는데 함수가 생각보다 길지만, 각 위치가 어떤 의미 인지 이해하면서 작성하면 어럽지 않게 작성할 수 있다.
일단 Rank 함수의 기본꼴은 rank() over() 이라고 생각하고 rank() 안에 아무것도 적어주지 않는다.
우리는 over () 안에 적어줄 건데,
rank() over(partition by 순위를 매길 컬럼, order by 순위 기준 컬럼 (desc 오름차순or내림차순))이러한 형태인데 실습문제는 음식타입별로 주문 건수가 가장 많은 순위 상점이니깐
순위를 매길 컬럼에는 음식타입별이기 때문에 cuisine_type이 들어가야하고
순위 기준 컬럼은 주문 건수이기 때문에 cnt_order가 들어간다.
그리고 마지막으로 주문 건수가 많은 순서이니깐 내림차순이 되야해서 desc를 붙여줄 것 이다.
Query문으로 작성해보면,
select cuisine_type,
restaurant_name,
rank() over(partition by cuisine_type order by cnt_order desc) ranking,
cnt_order
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a먼저 작성한 Query문을 SubQuery문을 만들어주고 우리가 결과로 나타내야하는 컬럼들을 순서대로 작성해준다.
그리고 순위를 매기기 위해 위에서 설명한 것 처럼 rank 함수를 작성해주면 아래와 같은 결과를 얻을 수 있다.
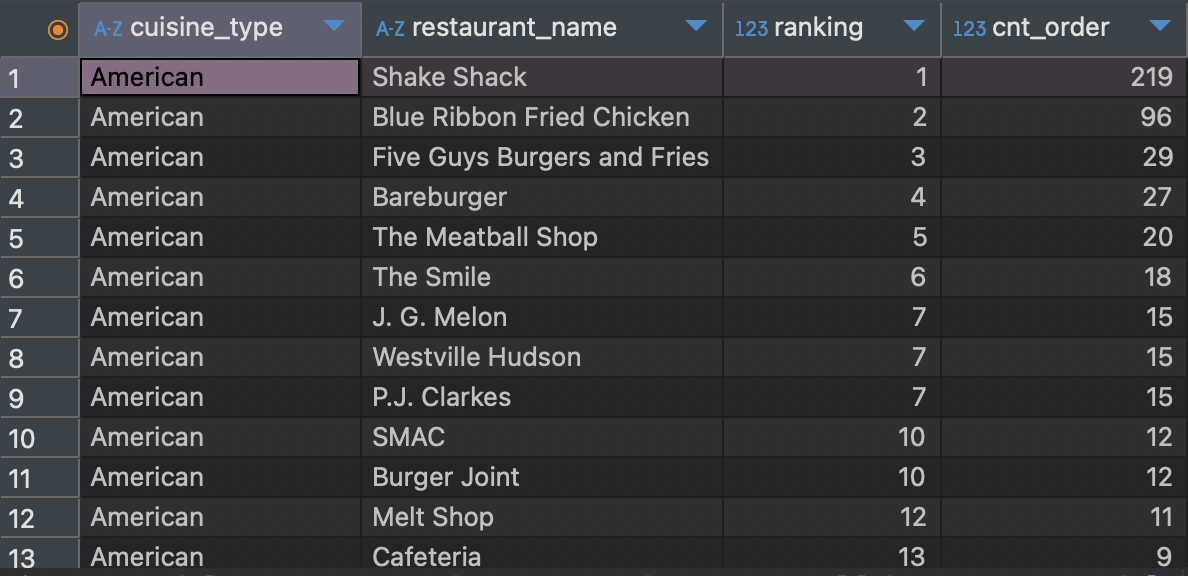
American 음식점이 많아서 안 보이지만 결과를 아래로 내리면 타입별 음식들로 순위가 나누어져 있다.
위 결과는 American 음식의 순위만 나타난 것 이고 우리는 3순위 안에 드는 상점만 아는 것을 원하기 때문에 subquery문을 한번 더 사용하여 마무리 하겠다.
select cuisine_type,
restaurant_name,
cnt_order,
ranking "순위"
from
(
select cuisine_type,
restaurant_name,
rank() over(partition by cuisine_type order by cnt_order desc) ranking,
cnt_order
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a
) b
where ranking <= 3
order by 1, 4
subquery문이 2개가 되어서 길어보이지만 내용은 그렇게 어렵지 않다.
앞에서 순서대로 작성한 Query문에서 계속 추가적으로 작성하였고, 저는 순위가 컬럼 맨 뒤에 나타나는 게 보기 좋을 것 같아 마지막에 컬럼 순서만 바꿔주었고 순위 3등 안에 드는 상점만 나타내기 위해 마지막에 where 절을 이용해 ranking이 3보다 낮은 수만 나타내게 하였고 order by를 사용하여 음식타입별과 순위별로 정렬하였다.
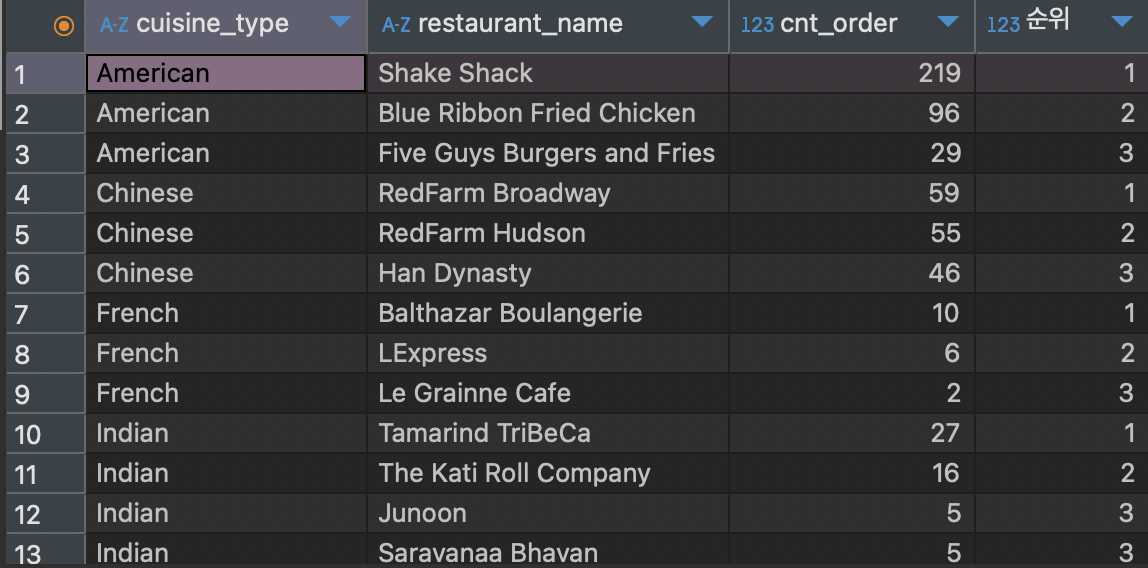
실습에서 요구한 대로 음식타입별 주문 건수가 3순위 안에 드는 결과를 얻을 수 있다.
이제 SUM 함수에 대해 알아보자.
sum 함수는 앞에서 배운 기능과 동일하지만 누적합이 필요하거나 카테고리별 합계 컬럼과 원본 컬럼을 함께 이용할 때 편리합니다.
바로 실습을 통해 알아보자.
1) 각 음식점의 주문건이 해당 음식 타입에서 차지하는 비율을 구하고 주문건이 낮은 순으로 정렬했을 때 누적 합 구하기.
이번 건 한 번에 작성한 후에 하나씩 알아보자.
select cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over (partition by cuisine_type) sum_cuisine,
sum(cnt_order) over (partition by cuisine_type order by cnt_order, restaurant_name) cum_cuisine
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a
order by cuisine_type , cnt_order, cum_cuisine
항상 subquery문 부터 알아봐야한다.
음식타입과 음식점 이름, 그리고 주문 건수를 그룹별로 결과가 나오게 작성하였고 위에선 이제 sum 함수의 기본 형태를 볼건데, 앞에서 했던 rank 함수 형태와 크게 다르지 않지만 sum() over() 형태에서 sum(합 할 컬럼)을 적어줘야한다.
그리고 나머지 형태는 rank 함수와 다르지 않다. 무슨 컬럼을 기준으로 할 건지 그리고 정렬을 어떤 컬럼 기준으로 할건지 적어준다.
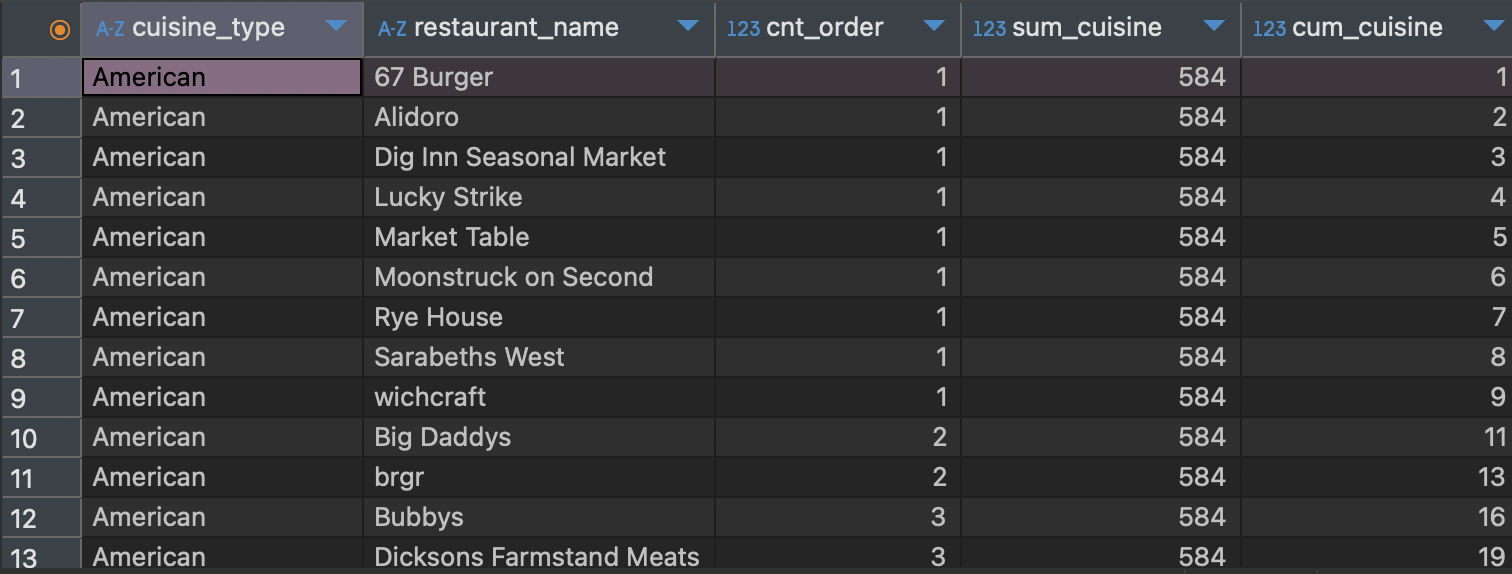
이렇게 각 음식점별 타입별 주문 건수가 나오고 그 합계가 몇 개 인지 그리고 누적합을 볼 수 있다.
마지막으로
날짜 포맷과 조건까지 한 번에 끝낼 수 있는 포맷 함수.
SQL에서 연산은 숫자와 문자 외에 날짜까지 가능하다.
date 함수를 통해 활용할 수 있는 기능을 알아보자.
우리가 결과창을 보면 숫자 타입, 문자 타입이 존재하는 것을 알 수 있는데 이때 날짜 타입도 존재한다.
우리 테이블에서 date 컬럼을 사용하여 date 함수를 이용해보자.
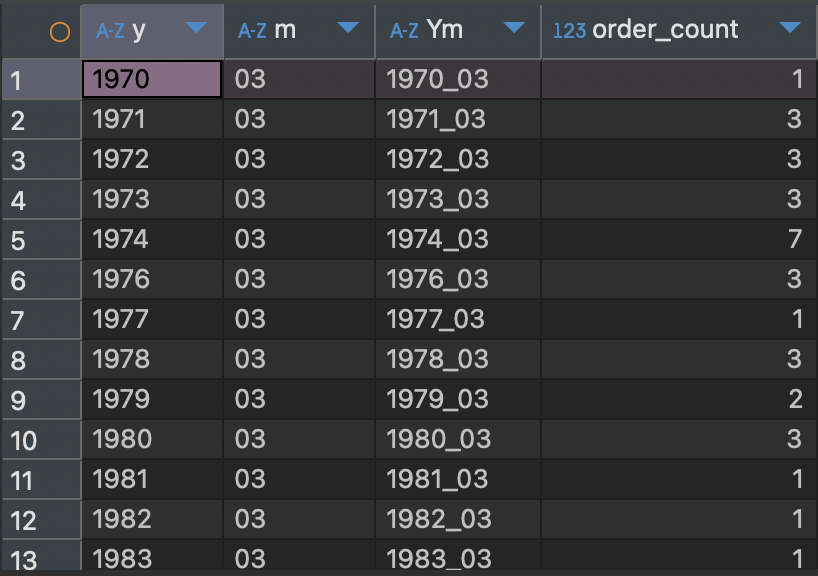
select date_format(date(date), '%Y') y,
date_format(date(date), '%m') m,
date_format(date(date), '%Y_%m') Ym,
count(1) order_count
from food_orders a inner join payments b on a.order_id=b.order_id
where date_format(date(date), '%m')='03'
group by 1, 2
order by 1
date(date)가 작성된 모습을 볼 수 있는데, date(컬럼) 이렇게 봐야한다. date()는 함수이며 () 안의 date는 컬럼이다.
맨 처음 date(date)를 작성하면 date 컬럼의 모든 날짜(년도, 월, 일)을 다 가져온다.
우리는 여기서 date_format을 이용하여 원하는 날짜만 가져올 수 있다.
위 query문 처럼 date_format(date(date), '%Y') y 는 '년도'만 가져오게 하는 것이다.
%Y를 이용하면 2021 이라는 데이터를 가져오지만 이때 소문자 y 를 작성하면 2021에서 21만 가져올 수도 있다.
그리고 '%Y%m' 이런식으로 작성하면 198903, 즉 1989년 3월인데 알아보기 힘들기 때문에 %Y_%m' 이렇게 작성하니
1989_03 이렇게 결과가 나오기에 더욱 보기 쉽다.
query문을 보니 where 절을 통해 '%m'이 03일 때만 나타내려고 하는 걸 보니 3월에 주문 건수를 알기 위해 작성한 듯 하고 group by 로 년도별 3월 주문 건수만 결과를 나타낸 것을 알 수 있다.
'TIL > SQL' 카테고리의 다른 글
| TIL 2024-09-25(SQL) (2) | 2024.09.25 |
|---|---|
| TIL 2024-08-30 (SQL - 4주차) (1) | 2024.08.30 |
| TIL 2024-08-29 (SQL - 3주차) (0) | 2024.08.29 |
| TIL 2024-08-28 (SQL - 2주차) (1) | 2024.08.28 |
| TIL 2024-08-26 (SQL - 1주차) (0) | 2024.08.27 |