8) LOL을 하다가 홧병이 나서 병원을 찾아왔습니다.
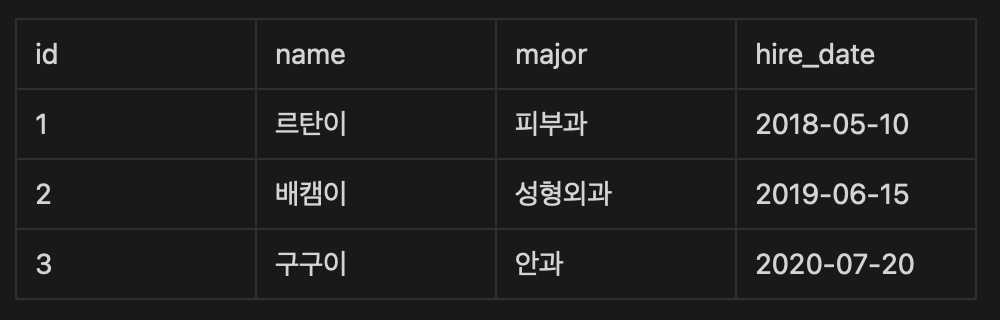
- doctors 테이블에서 전공(major)이 성형외과인 의사의 이름(name)을 알아내는 쿼리를 작성해주세요.
SELECT name
FROM doctors
WHERE major LIKE '성형외과'
의사의 이름을 알아내는 쿼리 이기에 SELECT에 name을 쓰고 전공이 성형외과인 의사라는 조건이 있기에 조건문(WHERE)을 사용한다. 여기서 특정 글자를 포함할 때 만 데이터를 가져오는 LIKE를 사용한다.
- doctors 테이블에서 각 전공(major) 별 의사 수를 계산하는 쿼리를 작성해주세요.
SELECT major, COUNT(1)
FROM doctors
GROUP BY 1
각 전공 별 이기 때문에 GRUOP BY로 중복되는 전공을 다 묶어주고 각 전공이 몇 개 있는지 확인한다면 의사 수도 확인할 수 있기에 COUNT(1)을 사용해준다.
여기서 GROUP BY 1 이란 SELECT에서 첫번째 쿼리를 뜻한다. major라고 적어도 된다.
- doctors 테이블에서 현재 날짜 기준으로 5년 이상 근무(hire_date)한 의사 수를 계산하는 쿼리를 작성해주세요.
SELECT COUNT(1) doctors_NUM
FROM doctors
WHERE DATEDIFF(CURDATE(), hire_date) >= 1825현재 날짜 기준를 하드코딩하면 매번 쿼리문을 바꿔줘야 하기에 CURDATE()를 사용해준다.
5년 이상 근무이기에 5년을 일수로 계산하면 1825일.
현재 날짜와 hire_date의 차이를 구하면 된다.
조건문(WHERE)을 사용하여 1825일 이상인 데이터만 조회하고 COUNT(1)을 이용하여 데이터의 갯수를 세주고 새로운 컬럼명을 지어주면 된다.
- doctors 테이블에서 각 의사의 근무(hire_date) 기간을 계산하는 쿼리를 작성해주세요.
SELECT *, DATEDIFF(CURDATE(), date) duration
FROM doctors
저번 사전퀘스트 문제와 매우 똑같은 문제가 나왔다.
위에서 문제에서 사용했던 DIFFDATE를 사용하여 두 날짜를 계산해주고 그것을 조회하기만 하면 된다.
9)아프면 안됩니다! 항상 건강 챙기세요!
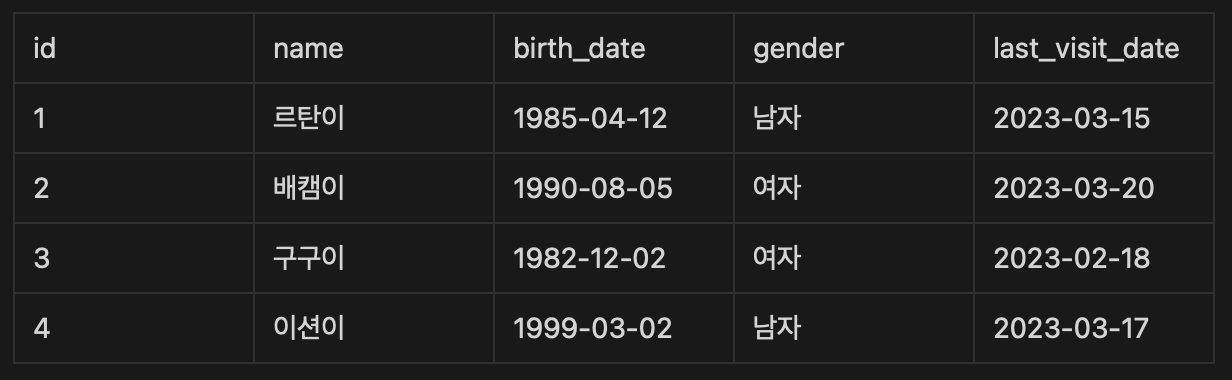
- patients 테이블에서 각 성별(gender)에 따른 환자 수를 계산하는 쿼리를 작성해주세요.
SELECT gender, COUNT(1)
FROM patients
GROUP BY 1각 성별에 따른 환자 수.
gerder를 GROUP BY로 중복되는 것들을 묶어주고 COUNT로 데이터의 갯수를 세어주면 된다.
- patients 테이블에서 현재 나이가 40세 이상인 환자들의 수를 계산하는 쿼리르 작성해주세요.
SELECT COUNT(1) patients_num
FROM
(
SELECT *, TIMESTAMPDIFF(year, birth_date, CURDATE()) age
FROM patients
)a
WHERE age >= 40현재 나이가 40세 이상이기에 birth_date와 현재 날짜의 연도 차이를 구하면 된다.
DATEDIFF는 일수 계산만 해주기에 여기선 TIMESTAMPDIFF를 사용해준다.
두 개의 차이는 SQL 사전퀘스트 5번 문제에 적혀있다.
연도 계산을 해주고 이것을 age라는 새로운 컬럼명을 주고 서브쿼리를 사용해 환자들의 수를 세어주고 조건문(WHERE)을 이용해서 age가 40 이상인 환자들의 수만 세어준다.
- 여기서 왜 굳이 한 번에 안 쓰고 서브쿼리를 사용했는가?
- WHERE절에 TIMESTAMPDIFF를 사용하면 에러가 발생.
- 아마도 조건 비교해야 하는 데이터가 너무 많기에 발생하는 에러 같다.
- patients 테이블에서 마지막 방문 날짜(last_visit_date)가 1년 이상 된 환자들을 선택하는 쿼리를 작성해주세요.
SELECT *
FROM patients
WHERE DATEDIFF(CURDATE(), last_visit_date) >= 365마지막 방문 날짜가 1년 이상 된 환자.
last_visit_date가 현재 날짜와 365일 이상 차이나는 환자들을 선택하면 된다.
여기선 일수만 있어도 되니 DATEDIFF문을 사용해준다.
- patients 테이블에서 생년월일이 1980년대 환자들의 수를 계산하는 쿼리를 작성해주세요.
SELECT COUNT(1) patients_num
FROM payments
WHERE DATE_FORMAT(date(birth_date), '%Y') LIKE '198%'생년월일이 1980년대 환자들의 수.
먼저 앞의 문제들처럼 날짜 계산이 아닌 것을 파악하고 우리가 원하는 건 1980년대 라는 것이다.
그렇다면 birth_date에서 년도만 뽑아오면 되기에 DATE_FORMAT 함수를 사용할 것이다.
- DATE_FORMAT(DATE(date 컬럼), '%(원하는 생년월일)')
- '%Y', '%m', '%d' 순서대로 연도, 월, 일
그렇다면 우리는 연도만 필요하기에 '%Y'를 사용하고 거기서 1980년대만 가져오고 싶기에
LIKE를 사용하여 '198%'.
198으로 시작하는 데이터만 조회하면 된다.
10) 이젠 테이블이 2개입니다
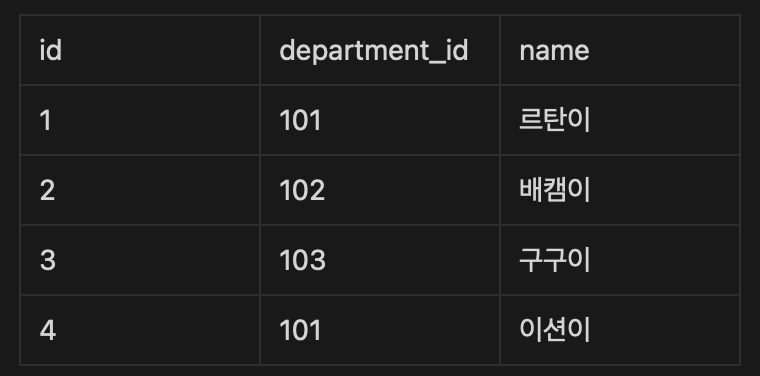
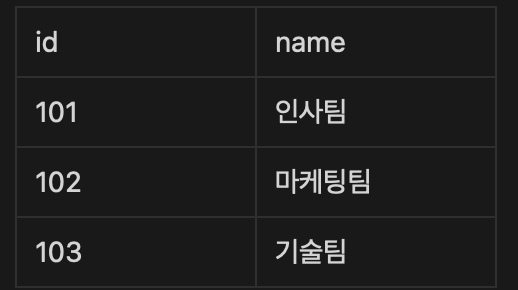
- 현재 존재하고 있는 총 부서의 수를 구하는 쿼리를 작성해주세요.
SELECT COUNT(1) "총 부서의 수"
FROM departments부서의 갯수는 department table 의 id or name 둘 중 하나의 데이터의 갯수만 세주면 됩니다.
그래서 departments의 테이블의 데이터 갯수를 세주었다.
- 모든 직원과 그들이 속한 부서의 이름을 나열하는 쿼리를 작성해주세요.
SELECT d.name, e.name
FROM departments d left join employees e on d.id = e.department_id두 데이터 테이블을 하나로 묶어주기 위해 join을 사용했다.
여기선 inner, left 둘 중 어떤 것이든 사용해도 되는데 두 개의 차이는,
- inner : 모든 컬럼의 데이터가 존재하는 데이터만 조회.
- 즉 하나의 컬럼이라도 NULL이 들어간다면 조회되지 않음.
- left : 모든 컬럼의 데이터를 조회.
- 만약 컬럼에 데이터가 빈다면 NULL값으로 데이터가 존재하지 않는다고 표시된다.
모든 직원과 그들이 속한 부서의 이름.
이게 2개가 필요하기에 두 개의 테이블을 묶어준다.
이때 무슨 컬럼으로 묶어주냐가 중요한데 같은 데이터를 가지고 있는 컬럼들을 이용해준다.
join을 하였을 때 컬럼명 앞에 어떤 테이블에서 컬럼을 가져왔는지 정확히 명시해야한다.
d.name, e.name 처럼 말이다.
- '기술팀' 부서에 속한 직원들의 이름을 나열하는 쿼리를 작성해주세요.
SELECT d.name, e.name
FROM departments d left join employees e on d.id = e.department_id
WHERE d.name LIKE '기술팀'
두 테이블을 join만 한다면 그 뒤 부턴 어렵지 않게 평소 해왔던대로 하면 된다.
기술팀 부서에 속한 직원들의 이름을 나열.
d.name이 부서 이름이니 LIKE를 사용하여 기술팀 데이터만 가져오면 된다.
- 부서별로 직원 수를 계산하는 쿼리를 작성해주세요.
SELECT d.name, COUNT(1) employ_num
FROM departments d left join employees e on d.id = e.department_id
GROUP BY d.name부서별로 직원의 수를 계산.
당연히 부서별 이기 때문에 GROUP BY를 사용하여 부서별로 중복되는 데이터를 묶어주고, COUNT(1)로 데이터의 갯수를 세주면 된다.
- 직원이 없는 부서의 이름을 찾는 쿼리를 작성해주세요.
SELECT d.name
FROM departments d left join employees e on d.id = e.department_id
WHERE e.department_id is NULL직원이 없는 부서의 이름.
지금 테이블에는 직원이 없는 부서가 없지만 나중에 데이터 테이블이 더 커지면 충분히 생길 수 있다.
조회 시 부서의 이름이 나와야 하기에 d.name 컬럼을 적어주고,
name은 존재하는데 부서 아이디가 없는 데이터를 찾아야하기에
e.department_id가 NULL 인 값만 조회한다.
- '마케팅팀' 부서에만 속한 직원들의 이름을 나열하는 쿼리를 작성해주세요.
SELECT e.name
FROM departments d left join employees e on d.id = e.department_id
WHERE d.name <> '인사팀' AND d.name <> '기술팀'이 문제에서 나는 부서에'만' 이라는 글자가 눈에 들어왔다.
위에 데이터 테이블 2개를 보면 한 사람이 여러 부서에 속해있지 않지만 만약에 한 사람이 여러 부서에 속해있다면 그 사람의 이름을 조회했을 때 그 사람의 이름으로 여러 로우가 나올 것 이다.
EX) 그냥 d.name = '마케팅팀' 으로 한다면, a라는 사람과 b라는 사람이 둘 다 마케팅팀이지만, a는 기술팀에도 속해있고 b는 마케팅팀에만 있다고 하면 우리는 결과를 조회했을 시 a, b 둘 다 조회 되는 걸 볼 수 있다.
하지만 우리는 b 만 출력되기를 원하니 d.name = '마케팅팀' 이라고 하면 안되고 나머지 기술팀이 속해있다면 제외하는 조건문(WHERE)을 적어야한다.
지금은 3개의 부서 밖에 없기에 나머지 2개를 제외하는 조건문을 적어주면 된다.
'TIL > 사전캠프 퀘스트' 카테고리의 다른 글
| TIL 2024-09-20( JAVA_걷기반 반복문 연습하기 Part 1~3) (0) | 2024.09.20 |
|---|---|
| TIL 2024-09-20( SQL_걷기반 마지막 문제 ) (1) | 2024.09.20 |
| TIL 2024-09-13 ( SQL_걷기반 6~7 ) (1) | 2024.09.13 |
| TIL 2024-09-12 ( SQL_걷기반 2~5 ) (0) | 2024.09.12 |
| 1) 돈을 벌기 위해 일 합시다! (0) | 2024.08.27 |